이전 글에서 'Row_Number'를 이용하여 검색된 결과에 순서대로 번호를 부여한 후 이 번호를 기반으로 'bettwen'으로 필요한 범위를 잘라내는 방법을 설명하였습니다.
동적 코드 없이도 코드가 깔끔하지만 속도가 너무 안 났고 그 원인을 분석해보니 셀랙트 부분에 있는 'Case'문이 문제였습니다.
(참고 : [MSSQL] MSSQL의 페이징 쿼리 고찰 - 1. Row_Number + bettwen)
이 문제를 해결할 수 있도록 튜닝해 봅시다.
*글을 읽기전에 이전글( [MSSQL] MSSQL의 페이징 쿼리 고찰 - 0. 테스트 환경 만들기(클릭) )을 보고 오시는 것이 좋습니다.*
1. 사용 방법
사용 방법은 다음과 같습니다.
Select Row_Number() Over ( Order By [넘버링 기준 컬럼] Asc ) AS [Row_Number()로 만든 순서 컬럼명], [출력할 컬럼]
From [테이블]
Where [조건] Order by [Case 문]
'[Case 문]'은 'Order by'절에서 'case' 사용하기와 동일 합니다.
(참고 : [MSSQL] 'Order by'절에서 'case'문 사용하기)
2. 페이징 코드
이제 튜닝된 코드를 확인해 봅시다.
2-1. 전체 코드
CREATE PROCEDURE [dbo].[spPageing_RowNumber_bettwen_Tuning]
AS
BEGIN
DECLARE @dataStart DATETIME, @dataEnd DATETIME
SET @dataStart = CURRENT_TIMESTAMP
Declare @nLanguage_Index int = 0
Declare @nPageNum int = 1
Declare @nOrderColumn int = 0
Declare @nSort int = 2
Declare @nSearchIndex int = 1
Declare @sSearch nvarchar(128) = ''
--한페이지에 보여질 글갯수
Declare @nPageSize int
--총 페이지 갯수
Declare @nTotalPage int
--총 글 갯수
Declare @nTotalCount int
--출력용 임시 테이블
Declare @tableData Table
( RowNum int
, nIndex int
, Data1 nvarchar(128)
, Data2 nvarchar(128)
, Data3 nvarchar(128)
, Data4 int);
--페이지 정보 저장용
Declare @tableInfo Table
( TotalCount bigint
, TotalPage int);
--한페이지에 몇개의 글을 출력할지 설정값을 받아온다.
Set @nPageSize = 10;
--조건에 맞게 테이블을 만든다.
--생성된 데이터를 빽업합니다.
Insert into @tableData Select Row_Number() Over ( Order By nIndex Asc ) AS rowNum
, nIndex
, Data1
, Data2
, Data3
, Data4
From tb_BigData1
Where (('' = @sSearch)
Or ((Case @nSearchIndex
When 1 Then Data1
When 2 Then Data2
When 3 Then Data3
When 4 Then CONVERT(nvarchar(128), Data4)
Else Data1
End) Like + '%' + @sSearch + '%'))
Order by case When @nSort <> 1 And @nSort <> 2
Then nIndex end Desc
, case when @nSort = 1
Then (Case @nOrderColumn
When 1 Then Data1
When 2 Then Data2
When 3 Then Data3
When 4 Then Data4
Else nIndex
End) end Asc
, case when @nSort = 2
Then (Case @nOrderColumn
When 1 Then Data1
When 2 Then Data2
When 3 Then Data3
When 4 Then Data4
Else nIndex
End) end Desc
--완성된 리스트를 가지고 필요한 정보를 추출한다.
--글수 구하기
Set @nTotalCount = (Select count(*)
From @tableData)
--페이지수 구하기
if( 0 < @nTotalCount )
Begin
Set @nTotalPage = (@nTotalCount / @nPageSize) + 1;
End
else
Begin
Set @nTotalPage = 0;
End
--글수와 페이지수 완성
Insert into @tableInfo( TotalCount
, TotalPage)
Values ( @nTotalCount
,@nTotalPage);
--완성된 정보 리턴
--페이지 정보
Select *
From @tableInfo as PageInfo;
--글목록
Select *
From @tableData as PageData
Where rowNum between ((@nPageNum - 1) * @nPageSize) + 1
And @nPageNum * @nPageSize
Order By rowNum Asc;
SET @dataEnd = CURRENT_TIMESTAMP
SELECT DATEDIFF(ms, @dataStart, @dataEnd)
END
2-2. 코드 분석
코드 분석은 테스트하기 전 왜 이런 코드가 되었는지를 설명하기 위한 것입니다.
결과에서 테스트를 통해 예상과 다르게 동작할 수 있으므로 주의가 필요합니다.
일단 Selet에 있던 'case'를 'Where'절로 옮겼습니다.
그리고 여러개의 'case'를 이용하여 정렬을 하고 있습니다.
'Order by'절에서 사용한 'case'문의 자세한 설명은 '[MSSQL] 'Order by'절에서 'case'문 사용하기'에서 했으므로 넘어가겠습니다.
(참고 : [MSSQL] 'Order by'절에서 'case'문 사용하기)
조건에
"case When @nSort <> 1 And @nSort <> 2 Then nIndex end Desc"
가 있는 이유는 자주 쓰는 조건을 빨리 명중 시키기 위해서 디폴트가 되는 조건을 미리 정의 한 것입니다.
코드를 더 간결하게 만들고 싶으시면 없어도 됩니다.
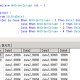
3. 결과
속도 (ms)
| 1회 | 2회 | 3회 | 4회 | 5회 | |
| 30만 | 523 | 446 | 596 | 540 | 503 |
| 100만 | 8556 | 8676 | 8393 | 8843 | 8990 |
이전 코드보다 속도가 많이 증가 하였습니다.
하지만 100만은 여전히 시간이 꽤 걸리네요 ㅡ,.ㅡ;

4. 결론
주관적인 점수(10점 만점)
| 가독성 | 8 | 일반적으로 가독성이 높으면 중복코드가 적다. |
| 속도 | 5 | 속도가빠르면 상대적으로 튜닝 가능성이 낮아 진다. |
| 중복 코드 | 7 | 중복이 없을 수록 높은 점수 |
| 튜닝 가능성 | 1 | 튜닝을 통해 성능개선이 얼마나 가능한지를 나타냄.(5%당 1점) |
가독성이 좋은 코드를 살짝 수정하여 성능을 개선한 코드라 가독성은 여전히 좋은 편입니다.
문제는 코드가 중복된다는 것인데... 어쩔 수 없죠 ㅎㅎㅎ
동적 쿼리를 쓰지 않은 것 치고는 중복코드가 없는 편입니다.
속도도 나쁘지 않습니다.
문제는 검색개수가 많을수록 느려진다는 것인데.... 대부분의 페이징쿼리가 이런 문제가 있죠.
그래서 보통 일정 개수만큼 잘라서 페이징하고 나머지는 페이지가 넘어가면 처리하는 방식도 많이 사용합니다.
(예> 100만 개까지 'top'으로 자른 후 검색하고 100만개 이후는 앞에 100만 개를 빼고 검색하는 방식)
마무리
저번 글에서도 이야기했던 'case'문 문제가 여기서도 발생합니다.
그래서 저런 코드가 되는 것이죠.
여러 개의 'case'문을 연결해도 속도 저하가 없다면 코드가 훨씬 깔끔해질 텐데 그게 아쉽습니다.
100만 개 검색에서는 속도가 늦은 편이기 때문에 너무 크지 않은 곳에서 쓸만 할 듯합니다.