



이 포스팅은 가능한 원론에 가깝게 설명하는 데 목표가 있는 포스팅입니다.
(이전 포스팅에서 이걸 안 지켜서.....)
이런 디자인 패턴을 도입하는 건 처리와 UI를 분리하기 위한 목적입니다.
이렇게 되면 처리 부분의 재사용성이 높아지기 때문입니다.
MVC 디자인 패턴은 뷰/컨트롤러/모델로 나뉩니다.
- 뷰 : UI/UX에 대한 사용자 입출력을 관리합니다.
모델의 상태를 표시하기 위해 모델과 연결됩니다.
- 컨트롤러 : 사용자로부터 받은 입력을 가공하고 모델로 전달합니다.
이 과정에서 모델과 뷰가 연결됩니다.
- 모델 : 전달받은 입력을 처리합니다.
뷰와 연결되었다면 모델이 뷰에 바로 업데이트를 요청할 수 있습니다.
아래와 같은 형태가 된다고 설명합니다.
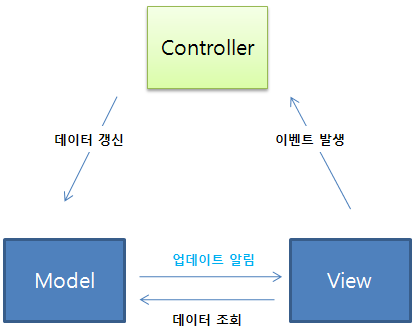
위 이미지에서는 모델과 뷰가 연결된 것처럼 보이지만 이런 패턴을 도입하는 이유 중 하나가 뷰와 모델을 분리하려는 것이기 때문에 가능하다면 완전히 분리해도 됩니다.
모델은 데이터 구조와 비즈니스 로직이 들어 있어야 합니다.
그런데 대부분의 비즈니스 로직은 여러 모델에 종속되어 있습니다.
이런 경우 비즈니스 로직만 관리하는 모델을 만드는 것이 좋습니다.
그러니 모델은 아주 크게 나누면
- 비즈니스 로직이 들어 있는 모델(편의상 ' 비즈니스 모델'이라고 부르겠습니다.)
- 데이터 구조가 들어 있는 모델(편의상 '스키마 모델'이라고 부르겠습니다.)
이렇게 나눌 수 있습니다.
스키마 모델에는 단일 모델에 대한 비즈니스 로직이 포함될 수 있습니다.
(예> 무결성 확보)
0. 프로젝트 생성
프로젝트는 콘솔 프로젝트로 만듭니다.
이 프로젝트의 동작은
1) 입력받은 숫자를 2배 하여
2) 모델에 저장하고
3) 이 내용을 출력합니다.
4) 단, Model2는 9의 보다 큰 값이 들어오면 9를 넣습니다.
1. 모델(Model) 생성
모델은 데이터를 저장과 처리를 위한 코드가 들어갑니다.
개인적으론 데이터를 직접적으로 가지고 있는 모델(데이터 구조)과 비즈니스 로직을 처리하기 위한 모델을 구분해야 한다는 입장이라 분리했습니다.
모델을 하나만 사용하는 비즈니스 로직이라면 꼭 분리할 필요는 없지만 일관성 유지를 위해 분리하는 것이 좋습니다.
필요에 따라서 비즈니스 로직을 컨트롤러에서 작성하는 경우도 있습니다.
1-1. 데이터 구조 모델
직접적으로 데이터를 가지고 있는 모델입니다.
데이터의 무결성을 지키기 위한 기능이 들어 있습니다.
#pragma once
/// <summary>
/// 10자리 문자열(끝문자 포함)을 가지고 있는 모델
/// </summary>
class Model1
{
private:
char* m_sData;
public :
Model1()
{
m_sData = new char[10];
}
~Model1()
{
}
public:
char* GetData()
{
return m_sData;
}
void SetData(char* sData)
{
char* sCut = new char[10];
if (10 < strlen(sData))
{//10자리가 넘는다.
//끝문자 1자리 제외하고 복사
strncpy(sCut, sData, 9);
}
else
{//10자리가 되지 않는다.
strcpy(sCut, sData);
}
m_sData = sCut;
}
};
34번 줄 : 끝 문자를 포함한 10자리만 저장하기 위해 문자열을 잘라줍니다.
#pragma once
/// <summary>
/// 0~9까지의 정수형 데이터를 저장하는 모델
/// </summary>
class Model2
{
private:
int m_nData;
public :
Model2()
{
m_nData = 0;
}
~Model2()
{
}
public:
int GetData()
{
return m_nData;
}
void SetData(int nData)
{
if (9 < nData)
{//9보다 크다.
nData = 9;
}
m_nData = nData;
}
};
27번 줄 : '9'보다 큰 데이터가 들어오면 '9'로 처리하는 Model2용 비즈니스 로직입니다.
1-2. 비즈니스 모델
Model1, Model2를 관리하고 기능적인 처리를 하는 모델입니다.
이 예제에서는 데이터 모델을 은닉했지만 꼭 필요한 것은 아닙니다.
#pragma once
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include "Model1.h"
#include "Model2.h"
class ModelBusiness
{
private:
/// <summary>
/// 모델1 - 은닉됨
/// </summary>
Model1* insModel1;
/// <summary>
/// 모델2 - 은닉됨
/// </summary>
Model2* insModel2;
public:
ModelBusiness()
{
insModel1 = new Model1();
insModel2 = new Model2();
}
~ModelBusiness()
{
}
public:
/// <summary>
/// 모델1의 데이터
/// </summary>
/// <returns></returns>
char* Model1Get()
{
return insModel1->GetData();
}
/// <summary>
/// 모델2의 데이터
/// </summary>
/// <returns></returns>
int Model2Get()
{
return insModel2->GetData();
}
public:
/// <summary>
/// 전달 받은 문자열을 숫자로 변환한 다음 *2한 후 문자열로 바꿔 Model1, Model2에 저장한다.
/// </summary>
/// <param name="sData"></param>
/// <returns></returns>
void DataProcessing(char* sData)
{
//전달 받은 문자열을 숫자로 변환한 다음 *2한 후 문자열로 바꿔 리턴한다.
char* sReturn = new char[10];
int nOneData = 0;
//입력받은 값을 숫자로 변환한다.
nOneData = atoi(sData);
//곱한다
nOneData = nOneData * 2;
//모델2에 저장
insModel2->SetData(nOneData);
//문자열로 바꿔준다.
sprintf(sReturn, "%d", nOneData);
//모델1에 저장
insModel1->SetData(sReturn);
}
};
56번 줄 : 전달받은 문자열을 숫자로 바꾸고 '곱하기2' 해주고 모델에 업데이트해 주는 함수입니다.
71번 줄 : Model2에 데이터를 저장하더라도 9보다 큰 수는 9로 저장된다는 걸 명심해야 합니다.
2. 뷰(View) 생성
뷰는 화면에 표시되는 모든 것을 처리합니다.
화면의 표시와 사용자의 응답에 대한 정보를 컨트롤러에 넘기는 역할도 합니다.
뷰에서 화면에 표시하기 위한 데이터처리를 하기도 합니다.
천 단위 콤마(,) 같은 처리는 뷰에서 하는 편이 더 효율적이죠.
다양하고 복잡한 UI/UX가 있는 프로젝트라면 이벤트나 콜백, 스레드제어 등등의 복잡한 작업들이 필요하기도 하지만
이 프로젝트는 콘솔에 글자 표시해주고 입력받은 데이터를 전달하는 역할이 다입니다.
이 예제에서는 뷰가 모든 UI에 표시되는 텍스트를 제어하고 있지만 필요에 따라서 컨트롤러가 할 수도 있습니다.
#pragma once
#include "conio.h"
class View
{
public:
View(void)
{
}
~View(void)
{
}
char* StartInput()
{
//메시지 표시
ShowMessage_Return("--------------아무숫자나 입력하세요------------");
ShowMessage_Return("(Model2는 0~9의 값만 저장할 수 있습니다.)");
//입력 UI
return ShowInputData();
}
void ShowResult(char* sResult, int nResult)
{
ShowMessage_Return("--------------결과------------");
ShowMessage("Model1 : ");
ShowMessage_Return(sResult);
//문자열로 바꿔준다.
char* sTemp = new char[10];
sprintf(sTemp, "%d", nResult);
ShowMessage("Model2 : ");
ShowMessage_Return(sTemp);
ShowMessage_Return("------------------------------");
}
/// <summary>
/// 화면에 입력받은 문자열을 그대로 출력하고 줄바꿈을 하지 않는다.
/// </summary>
/// <param name="sMessage"></param>
void ShowMessage(char* sMessage)
{
printf("%s", sMessage);
}
/// <summary>
/// 화면에 입력받은 문자열을 그대로 출력하고 줄바꿈을 한다.
/// </summary>
/// <param name="sMessage"></param>
void ShowMessage_Return(char *sMessage)
{
printf("%s\n", sMessage);
}
/// <summary>
/// 입력 UI 표시
/// </summary>
/// <returns></returns>
char* ShowInputData()
{
char* sReturn = new char[10];
scanf("%s", sReturn);
return sReturn;
}
/// <summary>
/// 아무키나 키입력 받을 때까지 대기하는 UI
/// </summary>
void Wait()
{
int temp = getch();
}
};
44번 줄 : 컨트롤러가 직접 'ShowMessage'함수를 호출하여 원하는 메시지를 출력할 수 있습니다.
3. 컨트롤러(Controller) 생성
컨트롤러는 뷰에서 온 명령을 제어합니다.
데이터 흐름을 제어하는 역할이 주요 역할입니다.
프로그램의 목적에 따라 데이터를 직접 처리하는 로직이 포함되거나
데이터를 뷰에다 전달하는 역할을 할 때도 있습니다.
필요에 따라 컨트롤러는 여러 개가 될 수도 있습니다.
비주얼 프로그램 툴들이 일반적으로 창 단위로 컨트롤러를 생성해 줍니다.
#pragma once
#include <stdlib.h>
#include <string.h>
#include "ModelBusiness.h"
#include "View.h"
class Controller
{
public:
/// <summary>
/// 모델
/// </summary>
ModelBusiness* insModelBusiness;
/// <summary>
/// 뷰
/// </summary>
View* insView;
Controller(ModelBusiness* model, View* view)
{
insModelBusiness = model;
insView = view;
}
~Controller(void)
{
}
void Start()
{
//View에 입력 UI 요청
char* sInput = insView->StartInput();
//입력받은 데이터를 비지니스 모델에 전달
insModelBusiness->DataProcessing(sInput);
//결과 출력 요청
insView->ShowResult(
insModelBusiness->Model1Get()
, insModelBusiness->Model2Get());
//뷰에 키 입력까지 대기 UI를 요청한다.
insView->Wait();
}
};
15번 줄 : 이 프로젝트에서는 직접 스키마 모델에 접근하지 않고 비즈니스 모델로만 처리합니다.
4. 샘플 소스
MVC는 샘플을 만들 때마다 이게 맞게 만든 건지 아닌지 모르겠습니다 ㅎㅎㅎㅎ
'ChatGPT'가 만든 샘플에 제가 만든 샘플을 섞어서 만들었습니다.

샘플 분석
이 프로젝트의 다이어그램을 보자면 다음과 같습니다.

앵? MVP에 더 가까운 거 아닌가요?
MVC도 뷰와 모델의 의존성을 낮추야 하므로 이런 간단한 프로젝트에서는 완전한 분리도 가능합니다.
가장 큰 차이점은
- MVC는 뷰와 모델 양쪽의 개체(생성된 인스턴스)에 접근하고
- MVP는 뷰에 대한 인터페이스에 접근하므로 인터페이스만 일치시키면 아무 뷰나 연결할 수 있다는 점이죠.
물론 이것도 칼로 베듯이 딱 잘리지 않을 때도 있습니다 ㅎㅎㅎㅎ
마무리
이론적으로야 재사용성 높여준다(이식성 좋은)지만 현실에서는 비즈니스 모델을 재사용하는 건 쉽지 않습니다.
그나마 스키마 모델 정도나 재사용할 수 있죠.
재사용성을 높인다는 개념으로 가려면 적어도 뷰를 완전히 분리해야 하는데 MVC는 여기에 적합하다고 보기 힘듭니다.
그러다 보니 '재사용 목적이 없다 + 빠르고 이해하기 쉬운 개발'이라는 곳에서는 오이려 적합한 패턴이라고 할 수 있습니다.
근데.....중간단계 프로젝트(대상이 사용자가 아니라 개발자인 프로젝트)를 제외한 대부분의 프로젝트에 여기에 속한다고 볼 수 있습니다.
개념적으로만 분리해 놓아도 소스 관리 및 협업에 많은 도움이 되기 때문에 MVC를 도입했다는 자각 없이 설계하다 보면 MVC와 비스므리하게 나오게 됩니다.
저 같은 경우 MVC 개념을 이해하기 전부터 설계할 때
- 스키마 모델
- 컨트롤러(+ 비즈니스 모델)
- 뷰
이렇게 분리하여 설계하였습니다.
비즈니스 모델이 컨트롤러로 들어간 이유는
'컨트롤러 : 뷰 : 비즈니스 모델'이 '1:1:1'로 매칭되는 경우가 많기 때문입니다.
뷰는 UI/UX 코드 때문에 복잡하지만 컨트롤러 비교적 한산하니 여기에 비즈니스 로직을 넣어 파일 숫자를 한 개씩 줄이는 것이죠.
(파일만 합치는 것이라 컨트롤러의 내용과 비즈니스 로직의 내용은 분리되어 관리됩니다.)
디자인 패턴에는 정답도 없고 지금 하는 프로젝트에 100% 적합한 패턴도 없습니다.
디자인 패턴이라는 것 자체를 가이드라인이라고 생각해야지 절대적으로 지켜야 할 룰이라고 생각하고 작업했다가 생산성이 떨어지거나 유지/보수가 안돼서 망하는 프로젝트 여럿 봤습니다.
(제가 직접 격었던 프로젝트중에는 MVP를 표방해서 만들어논 프로젝트였는데 유지보수하기 힘들다고 개발했던 회사가 버리고 떠나는 바람에 제가 있던 회사에서 유지/보수하기 쉽도록 재배치하면서 유지/보수했던 프로젝트도 있습니다 ㅎㅎㅎ)
여담으로
기존에 작성했던 포스팅에 틀린 내용도 있고 당시 생각했던 예제가 지금 보니 오히려 이해하기 힘들어서 보여서 다시 작성하는 등의 대대적인 수정이 있어서 글을 수정할지, 새로 작성할지 고민하다가 기존 글을 삭제하기로 결정했습니다.
잘못된 내용이 있는 걸 그대로 두기도 그렇고 수정하자니 새로 작성하는 것과 다른 게 없어서입니다.
이전 포스팅이 제가 설계하면서 겪었던 경험에 의해 변형된 MVC를 설계하고 있었는데
MVC개념이 제대로 잡히지 않았을 때부터 이렇게 설계하고 있었다 보니 일반론인 것처럼 이해하고 작성했더라고요.
근데 이걸 지금까지인지 못하고 있다가 얼마 전에서야 인지했습니다.
그렇다고 왜 이렇게 됐는지를 풀면 이런 변칙적인 MVC를 원론적인 것을 다루는 포스팅에서 다뤄야 하는 문제가 생겨서 그냥 포스팅 포기하고 삭제하기로 했습니다.
겸사겸사 흑역사도 지우고 말이죠 ㅎㅎㅎ



